Web Servers
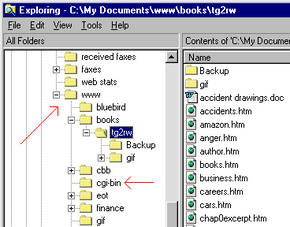
As described in the article How Web Servers Work, Web servers can be pretty simple. At their most basic, Web servers simply retrieve a file off the disk and send it down the wire to the requesting browser. Let's say you type in the URL http://www.bygpub.com/books/tg2rw/author.htm. The server gets a request for the file /books/tg2rw/author.htm. If you look at the following figure, you can see how the server resolves that request:
During setup, the Web server has been instructed to understand that c:\My Documents\www is the server's root directory. It then looks for /books/tg2rw/author.htm off of that root. When you ask for the URL http://www.bygpub.com/books/tg2rw/, the server understands that you are looking for the default file for that directory. It looks for several different files names to try to find the default file: index.html, index.htm, default.html, default.htm. Depending on the server, it may look for others as well. So the server turns http://www.bygpub.com/books/tg2rw/ into http://www.bygpub.com/books/tg2rw/index.htm and delivers that file. All other files must be specified by naming the files explicitly.
Advertisement
This is how all Web servers handle static files. Most Web servers also handle dynamic files -- through a mechanism called the Common Gateway Interface, or CGI. You have seen CGI in all sorts of places on the Web, although you may not have known it at the time. For example:
- Any guest book allows you to enter a message in an HTML form and then, the next time the guest book is viewed, the page will contain your new entry.
- The WHOIS form at Network Solutions allows you to enter a domain name on a form, and the page returned is different depending on the domain name entered.
- Any search engine lets you enter keywords on an HTML form, and then it dynamically creates a page based on the keywords you enter.
All of these dynamic pages use CGI.