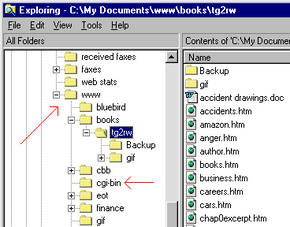
Assuming that you have access to a cgi-bin directory (see the previous section), and assuming that you know either the C programming language or PERL, you can do a whole bunch of interesting experiments with CGI to get your feet wet. Let's start by creating the simplest possible CGI script.
In the article How Web Pages Work, we examined the simplest possible HTML Web page. It looked something like this:
<html>
<body>
<h1>Hello there!</h1>
</body>
</html>
The simplest possible CGI script would, upon execution, create this simple, static page as its output. Here is how this CGI program would look if you wrote it in C:
#include <stdio.h>
int main()
{
printf("Content-type: text/html\n\n");
printf("<html>\n");
printf("<body>\n");
printf("<h1>Hello there!</h1>\n");
printf("</body>\n");
printf("</html>\n");
return 0;
}
On my Web server, I entered this program into the file simplest.c and then compiled it by saying:
gcc simplest.c -o simplest.cgi
(See How C Programming Works for details on compiling C programs.)
By placing simplest.cgi in the cgi-bin directory, it can be executed. As you can see, all that the script does is generate a page that says, "Hello there!" The only part that is unexpected is the line that says:
printf("Content-type: text/html\n\n");
The line "Content-type: text/html\n\n" is special piece of text that must be the first thing sent to the browser by any CGI script. As long as you remember to do that, everything will be fine. If you forget, the browser will reject the output of the script.
You can do the same thing in PERL. Type this PERL code into a file named simplest.pl:
#! /usr/bin/perl
print "Content-type: text/html\n\n";
print "<html><body><h1>Hello World!";
print "</h1></body></html>\n";
Place the file into your cgi-bin directory. On a UNIX machine, it may help to also type:
This tells UNIX that the script is executable.
You have just seen the basic idea behind CGI scripting. It is really that simple! A program executes and its output is sent to the browser that called the script. Normal output sent to stdout is what gets sent to the browser.
The whole point of CGI scripting, however, is to create dynamic content -- each time the script executes, the output should be different. After all, if the output is the same every time you run the script, then you might as well use a static page. The following C program demonstrates very simple dynamic content:
#include <stdio.h>
int incrementcount()
{
FILE *f;
int i;
f=fopen("count.txt", "r+");
if (!f)
{
sleep(1);
f=fopen("count.txt", "r+");
if (!f)
return -1;
}
fscanf(f, "%d", &i);
i++;
fseek(f,0,SEEK_SET);
fprintf(f, "%d", i);
fclose(f);
return i;
}
int main()
{
printf("Content-type: text/html\n\n");
printf("<html>\n");
printf("<body>\n");
printf("<h1>The current count is: ")
printf("%d</h1>\n", incrementcount());
printf("</body>\n");
printf("</html>\n");
return 0;
}
With a text editor, type this program into a file named count.c. Compile it by typing:
Create another text file named count.txt and place a single zero in it. By placing counter.cgi and count.txt in the cgi-bin directory, you can run the script. All that the script does is generate a page that says, "The current count is: X," where X increments once each time you run the script. Try running it several times and watch the content of the page change!
The count.txt file holds the current count, and the little incrementcount() function is the function that increments the count in the count.txt file. This function opens the count.txt file, reads the number from it, increments the number and writes it back to the file. The function actually tries to open the file twice. It does that just in case two people try to access the file simultaneously. It certainly is not a foolproof technique, but for something this simple it works. If the file cannot be opened on the second attempt, -1 is the error value returned to the caller. A more sophisticated program would recognize the -1 return value and generate an appropriate error message.