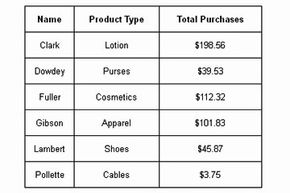
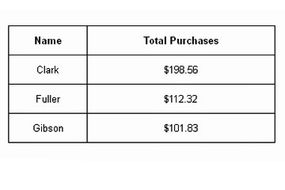
Based on the previous section, you might think that databases are fairly complex. That's a fair assumption, and it helps explain why data integration is still a developing discipline even though it's been around for decades. The goal of data integration is to gather data from different sources, combine it and present it in such a way that it appears to be a unified whole. However, the success of this process depends heavily on the data quality, as poor data can lead to inaccurate conclusions or insights.
Let's say you're about to leave on a trip and you want to see what traffic is like before you decide which route to take out of town. Here's how the different approaches to data integration would handle your query.
The manual integration approach would leave all the work to you. First, you'd have to know where to look for your data. You would need to know the physical location for both the traffic report and the map for your town. You would need to retrieve the traffic report and the map data directly from their respective databases, then compare the two sets of data against each other to figure out what's the best route out of town.
If you used a common user interface approach, you'd have to do a little less work. You'd use an interface such as the internet to make a query. The query results would appear as a view on the interface. You'd still have to compare the traffic report to the map to determine the best route, but at least the interface would take care of locating and retrieving the data.
Some integration approaches rely on applications to do all the work for you. The applications, often referred to as data integration tools, are specialized programs designed to locate, retrieve, and integrate the information for you. Data scientists often develop these applications to ensure that data integration processes run smoothly and deliver accurate results.
During the integration process, the applications must manipulate the data so that the information from one source is compatible with the information from the other source. In our example, that would mean you'd submit a query to an application and it would present a view that combined a map of your town with data from traffic reports. The problem with this approach is that applications become complex and difficult to program as the number of data sources and formats increases.
Then there's the common data storage method, also known as data warehousing. Using this method, all the data from the various databases you intend to integrate are extracted, transformed and loaded. That means that the data warehouse first pulls all the data from the various data sources. Then, the data warehouse converts all the data into a common format so that one set of data is compatible with another. Then it loads this new data into its own database. When you submit your query, the data warehouse locates the data, retrieves it and presents it to you in an integrated view.
Using our example, the data warehouse would locate the latest information it has on traffic reports and maps of your town. Then it would integrate the two together and send the view back to you. There are several advantages and drawbacks to this system, which we'll look into in the next section.
Most data integration system designers assume that the end goal is to create as little work for the end user as possible, so they tend to focus on applications and data warehousing techniques.
What is it that data warehouses do, exactly? Find out next!