One common application of CAPTCHA is for verifying online polls. In fact, a former Slashdot poll serves as an example of what can go wrong if pollsters don't implement filters on their surveys. In 1999, Slashdot published a poll that asked visitors to choose the graduate school that had the best program in computer science. Students from two universities -- Carnegie Mellon and MIT -- created automated programs called bots to vote repeatedly for their respective schools. While those two schools received thousands of votes, the other schools only had a few hundred each. If it's possible to create a program that can vote in a poll, how can we trust online poll results at all? A CAPTCHA form can help prevent programmers from taking advantage of the polling system.
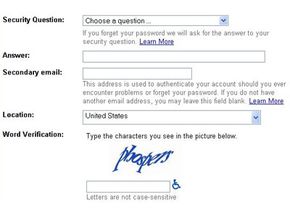
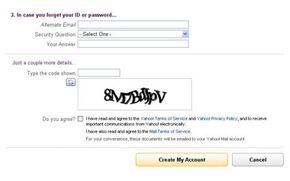
Registration forms on Web sites often use CAPTCHAs. For example, free Web-based e-mail services like Hotmail, Yahoo! Mail or Gmail allow people to create an e-mail account free of charge. Usually, users must provide some personal information when creating an account, but the services typically don't verify this information. They use CAPTCHAs to try to prevent spammers from using bots to generate hundreds of spam mail accounts.
Ticket brokers like TicketMaster also use CAPTCHA applications. These applications help prevent ticket scalpers from bombarding the service with massive ticket purchases for big events. Without some sort of filter, it's possible for a scalper to use a bot to place hundreds or thousands of ticket orders in a matter of seconds. Legitimate customers become victims as events sell out minutes after tickets become available. Scalpers then try to sell the tickets above face value. While CAPTCHA applications don't prevent scalping, they do make it more difficult to scalp tickets on a large scale.
Some Web pages have message boards or contact forms that allow visitors to either post messages to the site or send them directly to the Web administrators. To prevent an avalanche of spam, many of these sites have a CAPTCHA program to filter out the noise. A CAPTCHA won't stop someone who is determined to post a rude message or harass an administrator, but it will help prevent bots from posting messages automatically.
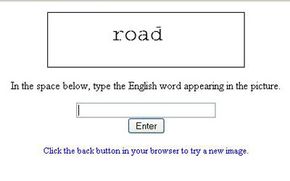
The most common form of CAPTCHA requires visitors to type in a word or series of letters and numbers that the application has distorted in some way. Some CAPTCHA creators came up with a way to increase the value of such an application: digitizing books. An application called reCAPTCHA harnesses users responses in CAPTCHA fields to verify the contents of a scanned piece of paper. Because computers aren't always able to identify words from a digital scan, humans have to verify what a printed page says. Then it's possible for search engines to search and index the contents of a scanned document.
Here's how it works: First, the administrator of the reCAPTCHA program digitally scans a book. Then, the reCAPTCHA program selects two words from the digitized image. The application already recognizes one of the words. If the visitor types that word into a field correctly, the application assumes the second word the user types is also correct. That second word goes into a pool of words that the application will present to other users. As each user types in a word, the application compares the word to the original answer. Eventually, the application receives enough responses to verify the word with a high degree of certainty. That word can then go into the verified pool.
It sounds time consuming, but remember that in this case the CAPTCHA is pulling double duty. Not only is it verifying the contents of a digitized book, it's also verifying that the people filling out the form are actually people. In turn, those people are gaining access to a service they want to use.
Next, we'll take a look at the process that goes into creating a CAPTCHA.