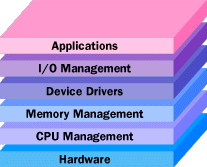
The operating system of a computer or other device allows it to handle multiple tasks at once. gilaxia/Getty Images
When you turn on your computer, it's nice to think that you're in control. There's the trusty mouse, which you can move anywhere on the screen, summoning up your music library or internet browser at the slightest whim. Although it's easy to feel like a director in front of your desktop or laptop, there's a lot going on inside, and the real person behind the curtain handling the necessary tasks is the operating system.
Microsoft Windows powers most of the computers we use for work or personal use. Macintosh computers come pre-loaded with macOS. Linux and UNIX operating systems are popular for digital content servers, but many distributions or distros, have become increasingly popular for everyday use. Regardless of your choice, without an operating system, you're not going to get anything done.
Advertisement
Other devices have their own operating systems. Google's Android and Apple's iOS are the most common smartphone OSes as of the 2020s, although some manufacturers have developed their own, mostly based on the Android operating system. Apple ships iPads with iPadOS, Apple watches with watchOS and Apple TV uses tvOS. And there are all kinds of other devices that have their own operating systems — think Internet of Things devices, smart TVs and the systems that run car infotainment systems. And that doesn't even include the complex systems needed in self-driving cars.
The purpose of an operating system is to organize and control hardware and software so that the device it lives in behaves in a flexible but predictable way. In this article, we'll tell you what a piece of software must do to be called an operating system, show you how the operating system in your desktop computer works and give you some examples of how to take control of the other operating systems around you.
A Windows 11 logo is seen on a smartphone screen with a Microsoft website in the background. Windows is probably the most common operating system.
Pavlo Gonchar/SOPA Images/LightRocket via Getty Images
Not all computers have operating systems. The computer that controls the microwave oven in your kitchen, for example, doesn't need an operating system. It has one set of tasks to perform, very straightforward input to expect (a numbered keypad and a few pre-set buttons) and simple, never-changing hardware to control. For a machine like this, an elaborate operating system would be unnecessary baggage, driving up the development and manufacturing costs significantly and adding complexity where none is required. Instead, the computer in a microwave oven simply runs a single hard-wired program called an embedded system all the time.
For other devices, an operating system creates the ability to:
Advertisement
Serve a variety of purposes
Interact with users in more complicated ways
Keep up with needs that change over time
All desktop computers have operating systems. The most common are the Windows family of operating systems developed by Microsoft, the Macintosh operating systems developed by Apple and the UNIX family of operating systems developed by a whole history of individuals, corporations and collaborators. There are hundreds of other operating systems available for special-purpose applications, including specializations for mainframes, robotics, manufacturing, real-time control systems and so on.
In any device that has an operating system, there's usually a way to make changes to how the device works. This is far from a happy accident; one of the reasons operating systems use portable code rather than permanent physical circuits is so that they can be changed or modified without having to scrap the whole device.
For a desktop computer user, this means you can add a new security update, system patch, new application or even an entirely new operating system rather than junk your computer and start again with a new one when you need to make a change. As long as you understand how an operating system works and how to get at it, in many cases you can change some of the ways it behaves.
Regardless of what device an operating system runs, what exactly can it do?
Advertisement
Operating System Functions
At the simplest level, an operating system does two things:
It manages the hardware and software resources of the system. In c omputers, tablets and smartphones these resources include the processors, memory, disk space and more.
It provides a stable, consistent way for applications to deal with the hardware without having to know all the details of the hardware.
The operating system controls every task your computer carries out and manages system resources to optimize performance.
The first task, managing the hardware and software resources, is very important, as various programs and input methods compete for the attention of the central processing unit (CPU) and demand memory, storage and input/output (I/O) bandwidth for their own purposes. In this capacity, the operating system plays the role of the good parent, making sure that each application gets its necessary resources while playing nicely with all the other applications, as well as husbanding the limited capacity of the system to the greatest good of all the users and applications.
Advertisement
The second task, providing a consistent user interface, is especially important if there is more than one of a particular type of computer using the operating system, or if the hardware making up the computer is ever open to change. A consistent application programming interface (API) allows a software developer to write an application on one computer and have a high level of confidence that it will run on another computer of the same type, even if the amount of memory or the quantity of storage is different on the two machines.
Even when a particular computer is unique, an operating system ensures that applications continue to run when hardware upgrades and updates occur. This is because the operating system — not the application — is charged with managing the hardware and the distribution of its resources. One of the challenges facing developers is keeping their operating systems flexible enough to run hardware from the thousands of vendors manufacturing computer equipment. Today's systems can accommodate thousands of different printers, disk drives and special peripherals in any possible combination.
Advertisement
Types of Operating Systems
This privacy notice appears on an iPhone 12 under the iOS 14.5.1 operating system. IOS is the system used by Apple products. Christoph Dernbach/picture alliance via Getty Images
Within the broad family of operating systems, there are several types, categorized based on the types of computers they control and the sort of applications they support. The categories are:
Real-time operating system (RTOS) - Real-time operating systems are used to control machinery, scientific instruments and industrial systems. An RTOS typically has very little user-interface capability, and no end-user utilities since the system will be a "sealed box" when delivered for use. It is important that an RTOS is managing the resources of the computer so that a particular operation executes in precisely the same amount of time every time it occurs. In a complex machine, having a part move more quickly just because system resources are available may be just as catastrophic as having it not move at all because the system is busy.
Single-user, single task - As the name implies, this operating system is designed to manage the computer so that one user can effectively do one thing at a time. MS-DOS is a good example of a single-user, single-task operating system.
Single-user, multitasking - This is the type of operating system most people use on their desktop and laptop computers today. Microsoft's Windows and Apple's macOS platforms are both examples of operating systems that lets a single user have several applications in operation at the same time. For example, it's entirely possible for a Windows user to be writing a note in a word processor while downloading a file from the internet and printing the text of an email message.
Multiuser - A multiuser operating system allows many different users to take advantage of a computer's resources simultaneously. The operating system must make sure that the requirements of the various users are balanced, and that each of the programs they are using has sufficient and separate resources so that a problem with one user doesn't affect the entire community of users. Unix, VMS and mainframe operating systems, such as MVS, are examples of multiuser operating systems.
Distributed - These operating systems manage multiple computers at the same time. Rather than using a single powerful computer to work on large problems, distributed OSes break it down into pieces among many smaller computers. You may find these systems in giant server farms, but hobbyists and educators create their own distributed systems too using inexpensive machines and even repurposed gaming consoles.
It's important to differentiate between multiuser operating systems and single-user operating systems that support networking. If you work in an office where a system administrator controls what software you can or can't have on your work computer, you are using a single-user system that is part of a network. You may print a document on a printer shared with other employees, or have a file server that stores your department's documents.
Advertisement
With the different types of operating systems in mind, it's time to look at the basic functions provided by an operating system.
Advertisement
Computer Operating Systems
When you turn on the power to a computer, the first program that runs is usually a set of instructions kept in the computer's firmware called the boot ROM. For a typical PC, this can be the basic input output system (BIOS), or on newer machines, the unified extensible firmware interface (UEFI). This code examines the system hardware to make sure everything is functioning properly and in the case of UEFI, that the boot software is legitimate and secure. Once the test has successfully completed, the firmware continues the boot process.
The bootstrap loader, or boot loader, is a small program that has a single function: It loads the operating system into memory and allows it to begin operation. In the most basic form, the bootstrap loader sets up the small driver programs that interface with and control the various hardware subsystems of the computer. It sets up the divisions of memory that hold the operating system, user information and applications. It establishes the data structures that hold the myriad signals, flags and semaphores that are used to communicate within and between the subsystems and applications of the computer. Then it turns control of the computer over to the operating system.
These tasks define the core of nearly all operating systems. Next, let's look at the tools the operating system uses to perform each of these functions.
Advertisement
Processor Management
The heart of managing the processor comes down to two related issues:
Ensuring that each process and application receives enough of the processor's time to function properly
Using as many processor cycles as possible for real work
The basic unit of software that the operating system deals with in scheduling the work done by the processor. Applications contain at least one process, and within each process there is at least one thread. Threads execute parts of the process code and operating systems m anage units even as small as threads, assigning the resources they need to function properly.
Advertisement
It's tempting to think of a process as an application, but that gives an incomplete picture of how processes relate to the operating system and hardware. The application you see (word processor, spreadsheet or game) is, indeed, a process, but that application may cause several other processes to begin, for tasks like communications with other devices or other computers. There are also numerous processes that run without giving you direct evidence that they ever exist. For example, an operating system can have dozens of background processes running to handle the network, memory management, disk management, virus checks and so on.
A process, then, is software that performs some action and can be controlled — by a user, by other applications or by the operating system.
It is processes, rather than applications, that the operating system controls and schedules for execution by the CPU. In a single-tasking system, the schedule is straightforward. The operating system allows the application to begin running, suspending the execution only long enough to deal with interrupts and user input.
Interrupts are special signals sent by hardware or software to the CPU. It's as if some part of the computer suddenly raised its hand to ask for the CPU's attention in a lively meeting. Sometimes the operating system schedules the priority of processes so that interrupts are masked — that is, the operating system ignores the interrupts from some sources so that a particular job can be finished as quickly as possible. Some interrupts (such as those from error conditions or problems with memory) are so important that they can't be ignored, such as the delivery of a message to you pointing out the battery in your laptop running out. These non-maskable interrupts (NMIs) must be dealt with immediately, regardless of the other tasks at hand.
While interrupts add some complication to the execution of processes in a single-tasking system, the job of the operating system becomes much more complicated in a multitasking system. Now, the operating system must arrange the execution of applications so that you believe that there are several things happening at once. This is complicated because each CPU can only do one thing at a time. Today's multicore processors and multiprocessor machines can handle more work, but each processor core is still capable of managing one task at a time.
To give the appearance of lots of things happening at the same time, the operating system has to switch between different processes thousands of times a second. Here's how it happens:
A process occupies a certain amount of RAM. It also makes use of registers, stacks and queues (forms of computer storage) within the CPU and operating-system memory space.
When two processes are multitasking, the operating system allots a certain number of CPU execution cycles to one program.
After that number of cycles, the operating system makes copies of all the registers, stacks and queues used by the processes, and notes the point at which the process paused in its execution.
It then loads all the registers, stacks and queues used by the second process and allows it a certain number of CPU cycles.
When those are complete, it makes copies of all the registers, stacks and queues used by the second program, and loads the first program.
Advertisement
Process Control Block
All of the information needed to keep track of a process when switching is kept in a data package called a process control block. The process control block typically contains:
An ID number that identifies the process
Pointers to the locations in the program and its data where processing last occurred
Register contents
States of various flags and switches
Pointers to the upper and lower bounds of the memory required for the process
A list of files opened by the process
The priority of the process
The status of all I/O devices needed by the process
Each process has a status associated with it. Many processes consume no CPU time until they get some sort of input. For example, a process might be waiting for a keystroke from the user. While it is waiting for the keystroke, it uses no CPU time. It is "suspended." When the keystroke arrives, the OS changes its status. When the status of the process changes from pending to active, for example or from suspended to running, the information in the process control block must be used like the data in any other program to direct execution of the task-switching portion of the operating system.
Advertisement
This process swapping happens without direct user interference, and each process gets enough CPU cycles to accomplish its task in a reasonable amount of time. Trouble may begin if the user tries to have too many processes functioning at the same time. The operating system itself requires some CPU cycles to perform the saving and swapping of all the registers, queues and stacks of the application processes.
Each process requires its own memory allocation, but the operating system must balance the load. The more applications you open, the less memory each app has to operate. If enough processes are started, and if the operating system hasn't been carefully designed, the system begins to use more of its available CPU cycles to swap between processes rather than running processes. When this happens, it's called thrashing, and it usually requires some sort of direct user intervention to stop processes and bring order back to the system. It's a lot like you trying to do too many things at once. Once you've hit your limit you will feel overwhelmed. That's what thrashing is to a computer.
Developers design their systems to avoid thrashing, but you can do your part by adding more RAM to your computer and closing applications you aren't using. That helps your OS manage resources more effectively and keep things running smoothly.
So far, all the scheduling we've discussed has concerned a single CPU. In a system with two or more CPUs, the operating system must divide the workload among the CPUs, trying to balance the demands of the required processes with the available cycles on the different processors. Asymmetric operating systems use one processor for their own needs and divide application processes among the remaining CPUs. Symmetric operating systems divide the work between the various processors, balancing demand versus availability even when the operating system itself is all that's running. They share the available memory. In fact, symmetric processing also applies to using multiple processor cores on the same chip.
If the operating system is the only software with execution needs, the processors are not the only resource that needs to be scheduled. Memory management is the next crucial step in making sure that all processes run smoothly.
Advertisement
Memory Storage and Management
IT specialist Mario Haustein works on a computer with the operating system Linux at the computer center of the Technical University in Chemnitz, Germany, March 8, 2017. Jan Woitas/picture alliance via Getty Images
When an operating system manages the computer's memory, there are two broad tasks to be accomplished:
The different types of memory in the system must be used properly so that each process can run most effectively.
The first task requires the operating system to set up memory boundaries for types of software and for individual applications.
Advertisement
As an example, let's look at an imaginary small system with 1 megabyte (1,000 kilobytes) of RAM. During the boot process, the operating system of our imaginary computer assigns enough memory to meet the needs of the operating system itself. Let's say that the operating system needs 300 kilobytes to run. Now, the operating system goes to the bottom of the pool of RAM and starts building up with the various driver software required to control the hardware subsystems of the computer. In our imaginary computer the drivers take up 200 kilobytes. So, once the operating system is completely loaded, there are 500 kilobytes remaining for application processes.
When applications begin to be loaded into memory, the operating system assigns them an amount of memory. As the next application launches, the operating system takes away some memory from other open applications to make sure the newest application has enough to run. With that ensured, the larger question is what to do if the 500-kilobyte application space is filled.
In most computers, it's possible to add memory beyond the original capacity. For example, you might expand the RAM in your computer from 8 to 16 gigabytes. But most of the information that an application stores in memory is not being used at any given moment. A processor can only access memory one location at a time, so the vast majority of RAM is unused at any moment. The operating system constantly swaps out the unused parts for the parts being used. This gives each process its own space and keeps them from corrupting one another. This technique is called virtual memory management.
Disk storage is only one of the memory types that must be managed by the operating system, and it's also the slowest. Ranked in order of speed, the types of memory in a computer system are:
High-speed cache: This is fast, relatively small amounts of memory that are available to the CPU through the fastest connections. Cache controllers predict which pieces of data the CPU will need next and pull it from main memory into high-speed cache to speed up system performance.
Main memory: This is the RAM that you see measured in gigabytes when you buy a computer.
Secondary memory: This is often a hard drive (HDD) or solid state drive (SSD) inside the computer which serves as virtual RAM under the control of the operating system.
The operating system must balance the needs of the various processes with the availability of the different types of memory, moving data in blocks called pages between available memory as the schedule of processes dictates.
Advertisement
Device Management
The path between the operating system and virtually all hardware not on the computer's motherboard goes through special programs called drivers. Much of a driver's function is to be the translator between the electrical signals of the hardware subsystems and the high-level programming languages of the operating system and application programs. Drivers take data that the operating system has defined as a file and translate them into streams of bits placed in specific locations on storage devices, or a series of laser pulses in a printer.
Because there are such wide differences in the hardware, there are differences in the way that the driver programs function. Most run when the device is required and function much the same as any other process. The operating system frequently assigns high-priority blocks to drivers so that the hardware resource can be released and readied for further use as quickly as possible.
Advertisement
One reason that drivers are separate from the operating system is so that new functions can be added to the driver — and thus to the hardware subsystems — without requiring the operating system itself to be modified, recompiled and redistributed. Many drivers are created or paid for by the manufacturer of the subsystems rather than the publisher of the operating system. That gives them the chance to update and enhance the input/output capabilities of the overall system.
Operating system publishers also create device drivers to update computers. While it is easier to expect up-to-date drivers for Windows and macOS from the large profitable companies that release them, Linux machines and other open-source OSes often rely on developers in their communities who are willing to volunteer their time and coding skills to provide drivers for systems and peripherals.
Managing input and output is largely a matter of managing queues and buffers, special storage facilities that take a stream of bits from a device — perhaps a keyboard or a serial port — hold those bits, and release them to the processor at a rate with which it can cope. This function is especially important when many processes are running and taking up processor time. The operating system instructs a buffer to continue taking input from the device, but to stop sending data to the processor while the process using the input is suspended. Then, when the process requiring input is made active once again, the operating system commands the buffer to send data. This process allows a keyboard or a modem to deal with external users or computers at a high speed even though there are times when the processor can't use input from those sources.
Managing all the resources of the computer system takes up most of the operating system's function and, in the case of real-time operating systems, may be virtually all the functionality required. For other operating systems, though, providing a relatively simple, consistent way for applications and humans to use the power of the hardware is a crucial part of their reason for existing.
Advertisement
Application Program Interfaces
Just as drivers provide a way for applications to make use of hardware subsystems without having to know every detail of the hardware's operation, application program interfaces (APIs) let application programmers use functions of the computer and operating system without having to directly keep track of all the details in the CPU's operation. Let's look at the example of creating a hard disk file for holding data to see why this can be important.
A programmer writing an application to record data from a scientific instrument might want to allow the scientist to specify the name of the file created. The operating system might provide an API function named MakeFile for creating files. When writing the program, the programmer would insert a line that looks like this:
Advertisement
MakeFile [1, %Name, 2]
In this example, the instruction tells the operating system to create a file that will allow random access to its data (signified by the 1 — the other option might be 0 for a serial file), will have a name typed in by the user (%Name) and will be a size that varies depending on how much data is stored in the file (signified by the 2 — other options might be zero for a fixed size, and 1 for a file that grows as data is added but does not shrink when data is removed). Now, let's look at what the operating system does to turn the instruction into action.
The operating system sends a query to the disk drive to get the location of the first available free storage location.
With that information, the operating system creates an entry in the file system showing the beginning and ending locations of the file, the name of the file, the file type, whether the file has been archived, which users have permission to look at or modify the file, and the date and time of the file's creation.
Because the programmer has written the program to use the API for disk storage, the programmer doesn't have to keep up with the instruction codes, data types and response codes for every possible hard disk and tape drive. The operating system, connected to drivers for the various hardware subsystems, deals with the changing details of the hardware. The programmer must simply write code for the API and trust the operating system to do the rest. Unfortunately, access to software via APIs may offer hackers an opportunity to use the application to their benefit and perhaps gain other access to the computer. That doesn't mean APIs are bad, but developers must make sure to avoid creating vulnerabilities and to patch them when they're identified.
Still, APIs have become one of the most hotly contested areas of the computer industry in recent years. Companies realize that programmers using their API will ultimately translate this into the ability to control and profit from a particular part of the industry. Developers know that providing applications like readers or viewers to the public at no charge will encourage consumers to use their software, although they may expect other developers to pay royalties to allow their software to provide the functions requested by the consumers. Many others make their APIs freely available to the public.
Advertisement
User Interface
Just as the API provides a consistent way for applications to use the resources of the computer system, a user interface (UI) brings structure to the interaction between a user and the computer. In the last decade, almost all development in user interfaces has been in the graphical user interface (GUI), with Apple's macOS and Microsoft's Windows receiving most of the attention and most of the market share.
Most (but not all!) distributions of Linux include a GUI. For GUI-based Linux distributions, the organization that releases the distribution chooses the desktop environment for the operating system. However, Linux users may decide to change the environment if they want to. Cinnamon, GNOME, KDE and Xfce are some popular desktop environments for Linux.
UNIX is often associated with a command line interface (CLI), or shell, that is more flexible and powerful than a GUI. A shell interface is text-only and requires the use of typed command words, which can be intimidating to users used to pointing and clicking. The Korn Shell and the C Shell are text-based interfaces that add important utilities, but their main purpose is to make it easier for the user to manipulate the functions of the operating system. But UNIX users can use a GUI, too. One of the benefits for developers is the ability to open more than one shell window at a time to work on multiple things at once.
Windows, macOS and Linux all offer shell or terminal applications for those who want or need to access a command line.
It's important to remember that in all these examples, the user interface is a program or set of programs that sits as a layer above the operating system itself. The core operating-system functions — the management of the computer system — lie in the kernel of the operating system. The ties between the operating-system kernel and the user interface, utilities and other software define many of the differences in operating systems today and will further define them in the future.
Operating System Development
For desktop systems, access to a network has become such an expected feature that in many ways it's hard to discuss an operating system without referring to its connections to other computers and servers. Operating system developers have made the internet the standard method for delivering crucial operating system updates and bug fixes. Although it's possible to receive these updates via DVD or flash drive, it's become rare.
One question concerning the future of operating systems concerns the ability of a particular philosophy of software distribution to create an operating system usable by corporations and consumers together.
Linux, the operating system created and distributed according to the principles of open source, has had a significant impact on operating systems in general. Most systems, drivers and utility programs are written by commercial organizations that distribute executable versions of their software — versions that normally can't be studied or altered, aka closed source. Open source requires the distribution of original source materials that can be studied, adapted and built upon, with the results once again freely distributed. In the desktop computer realm, this has led to the development and distribution of countless useful applications like the image manipulation program GIMP, the popular office suite LibreOffice and the popular web server Apache.
Many consumer devices like cell phones deliberately hide access to the operating system from the user, mostly to make sure that it's not inadvertently broken or removed. In many cases, they leave a "developer's mode" or "programmer's mode" open to allow changes to be made, if you're able to find it. Often these systems may be programmed in such a way that there are only a limited range of changes that can be made.
Ackerman, Evan. "Apex.OS: An Operating System for Autonomous Cars." IEEE Spectrum. Jan. 30, 2020. (Nov. 5, 2021) https://spectrum.ieee.org/apexos-operating-system-open-source-autonomous-cars
Apple, Inc. "Mac OS X: An Introduction for Support Providers." 2001. (Nov. 5, 2021) https://stuff.mit.edu/afs/athena/project/macosx/Mac_OS_X_Intro_for_Support.pdf
Barton, Elizabeth. "Folding@home: How Distributed Computing is Unraveling the Mysteries of Protein Folding." HCPLive. April 27, 2010. (Nov. 5, 2021) https://www.hcplive.com/view/protein_folding_playstation_3
"Boot Process for a Mac with Apple Silicon." Apple Platform Security. Apple Inc. Feb. 18, 2021. (Nov. 5, 2021) https://support.apple.com/guide/security/boot-process-secac71d5623/web
Both, David. "The Central Processing Unit (CPU): Its Components and Functionality." Red Hat. July 23, 2020. (Nov. 5, 2021) https://www.redhat.com/sysadmin/cpu-components-functionality
Brandom, Russell and Robertson, Adi. "Supreme Court Sides with Google in Oracle's API Copyright Case." The Verge. April 5, 2021. (Nov. 5, 2021) https://www.theverge.com/2021/4/5/22367851/google-oracle-supreme-court-ruling-java-android-api
Brooks, Gray. "Benefits of APIs" Digital.gov. March 12, 2013. (Nov. 5, 2021) https://digital.gov/2013/03/12/benefits-of-apis/
Bryanpwo. "How to Install Desktop Environments Next to Your Existing Ones." Discovery. EndeavourOS. March 24, 2021. (Nov. 5, 2021) https://discovery.endeavouros.com/general-system-settings/how-to-install-desktop-environments-next-to-your-existing-ones/2021/03/
Bryant, Randal E., and O'Hallaron, David R. "Virtual Memory." In Computer Systems: A Programmer's Perspective, 3rd Ed. Boston: Pearson Education. 2016. (Nov. 5, 2021) http://www.csapp.cs.cmu.edu/2e/ch9-preview.pdf
"Main Memory." University of Illinois Chicago. 2006. (Nov. 5, 2021) https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/8_MainMemory.html
"Classification of Operating Systems." In CIS 111: Introduction to Operating Systems. Olympic College. (Nov. 5, 2021) http://cis2.oc.ctc.edu/oc_apps/Westlund/xbook/xbook.php?unit=01&proc=page&numb=3
Denning, Peter J. "Multitasking Without Trashing." Communications of the ACM. 60(4), 32-34. September 2017. (Nov. 5, 2021) https://cacm.acm.org/magazines/2017/9/220424-multitasking-without-thrashing/fulltext#body-5
Document Foundation. "LibreOffice: The Document Foundation." (Nov. 5, 2021) https://www.libreoffice.org/
Duarte, Gustavo. "How computers boot up." Gustavo Duarte: Software, Computers and Business. June 5, 2008. (Nov. 4, 2021) http://duartes.org/gustavo/blog/post/how-computers-boot-up
Electronic Frontier Foundation. "Oracle v. Google." (Nov. 5, 2021) https://www.eff.org/cases/oracle-v-google
"ENIAC - The History of the First Computer." Hyperaxion. March 11, 2020. (Nov. 5, 2021) https://hyperaxion.com/technology/eniac-first-computer/
"File Sharing Over a Network in Windows 10." Microsoft Support. (Nov. 5, 2021) https://support.microsoft.com/en-us/windows/file-sharing-over-a-network-in-windows-10-b58704b2-f53a-4b82-7bc1-80f9994725bf
"Get More Done with Multitasking in Windows 11." Microsoft Support. (Nov. 5, 2021) https://support.microsoft.com/en-us/windows/get-more-done-with-multitasking-in-windows-11-b4fa0333-98f8-ef43-e25c-06d4fb1d6960
GIMP Team. "GIMP: GNU Image Manipulation Program." (Nov. 5, 2021) https://www.gimp.org/
Holmes, Jake and Alaniz, Anthony. "Every Car Infotainment System Available in 2020." Road Show by Cnet. Oct. 28, 2019. (Nov. 5, 2021) https://www.cnet.com/roadshow/news/car-infotainment-system-automotive-tech-guide/
Jones, M. "Inside the Linux 2.6 Completely Fair Scheduler." IBM Developer. Dec. 15, 2009. (Nov. 5, 2021) https://developer.ibm.com/tutorials/l-completely-fair-scheduler/?mhsrc=ibmsearch_a&mhq=symmetric%20process
Jones, M. "Inside the Linux Boot Process." IBM Developer. May 31, 2006. (Nov. 5, 2021) https://developer.ibm.com/articles/l-linuxboot/
Kelm, Robert. "What is Embedded System Design? Defining an Electrical Engineering Field." All About Circuits. Aug. 6, 2018. (Nov. 5, 2021) https://www.allaboutcircuits.com/technical-articles/what-is-embedded-design-embedded-system-design-firmware/
Ku, Andrew. "Microsoft Surface Review, Part 1: Performance and Display Quality." Tom's Hardware. Nov. 5, 2012. (Nov. 5, 2021) https://www.tomshardware.com/reviews/surface-benchmarks-windows-rt,3335-3.html
Linux.com Editorial Staff. "All About Linux Swap Space." Linux.com. Sept. 7, 2007. (Nov. 5, 2021) https://www.linux.com/news/all-about-linux-swap-space/
Lunduke, Bryan. "Without a GUI—How to Live Entirely in a Terminal." Linux Journal. June 28, 2019. (Nov. 5, 2021) https://www.linuxjournal.com/content/without-gui-how-live-entirely-terminal
Lydia. "Advantages and Disadvantages of API for Business." OpenVPN. (Nov. 5, 2021) https://openvpn.net/blog/advantages-and-disadvantages-of-api-for-business/
"Networking." IBM Cloud Learn Hub. IBM. March 17, 2021. (Nov. 5, 2021) https://www.ibm.com/cloud/learn/networking-a-complete-guide
Open Source Initiative. "The Open Source Definition." March 22, 2007. (Nov. 5, 2021) https://opensource.org/osd
"Operating Systems: Homework I Solution." University of Massachusetts (archived on Internet Archive). (Nov. 5, 2021) https://web.archive.org/web/20190320223658/http:/ecs.umass.edu/ece/andras/courses/ECE397A/homeworks/hw1soln.html
Pal, Trishla. "Memory Management in Operating Systems - Simple Explanation." Technobyte. (Nov. 5, 2021) https://technobyte.org/memory-management-os-simple-explanation/
Riley, Kurt. "Korn Shell Scripting: A Beginner's Guide." IBM Developer. June 17, 2008. (Nov. 5, 2021) https://developer.ibm.com/articles/au-kornshellscripting/
Russinovich, Mark E. and David A. Solomon. "Processes, Threads and Jobs." Microsoft Windows Internals, Fourth Edition: Microsoft Windows Server 2003, Windows XP and Windows 2000. (Nov. 4, 2021) https://web.archive.org/web/20060701201904/http://download.microsoft.com/download/5/b/3/5b38800c-ba6e-4023-9078-6e9ce2383e65/C06X1116607.pdf
Mullins, Robert. "Distributed Computing." University of Cambridge Department of Computer Science and Technology. 2012. (Nov. 5, 2021) https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/distributed-computing/
Vivian, Amy. "What is a driver?" Windows Hardware Developer. Microsoft. Aug. 8, 2021. (Nov. 5, 2021) https://docs.microsoft.com/en-us/windows-hardware/drivers/gettingstarted/what-is-a-driver-
W3Schools. "What is Command Line Interface (CLI)?" (Nov. 5, 2021) https://www.w3schools.com/whatis/whatis_cli.asp
WDD Staff. "Operating System Interface Design Between 1981-2009." Web Designer Depot. March 11, 2009. (Nov. 15, 2021) https://www.webdesignerdepot.com/2009/03/operating-system-interface-design-between-1981-2009/
"What is a Real-Time Operating System (RTOS)?" National Instruments. Sept. 3, 2020. (Nov. 5, 2021) https://www.ni.com/en-us/innovations/white-papers/07/what-is-a-real-time-operating-system—rtos—.html
"What is Distributed Computing." TXSeries for Multiplatforms. IBM. 2015. (Nov. 5, 2021) https://www.ibm.com/docs/en/txseries/8.2?topic=overview-what-is-distributed-computing
White, Ron and Timothy Edward Downs. How Computers Work: The Evolution of Technology, 10th ed. Indianapolis, Ind.: Que. 2015. (Nov. 6, 2021) https://learning.oreilly.com/library/view/how-computers-work/9780133096798/