To understand parallel processing, we need to look at the four basic programming models. Computer scientists define these models based on two factors: the number of instruction streams and the number of data streams the computer handles. Instruction streams are algorithms. An algorithm is just a series of steps designed to solve a particular problem. Data streams are information pulled from computer memory used as input values to the algorithms. The processor plugs the values from the data stream into the algorithms from the instruction stream. Then, it initiates the operation to obtain a result.
Single Instruction, Single Data (SISD) computers have one processor that handles one algorithm using one source of data at a time. The computer tackles and processes each task in order, so sometimes people use the word "sequential" to describe SISD computers. They aren't capable of performing parallel processing on their own.
Multiple Instruction, Single Data (MISD) computers have multiple processors. Each processor uses a different algorithm but uses the same shared input data. MISD computers can analyze the same set of data using several different operations at the same time. The number of operations depends upon the number of processors. There aren't many actual examples of MISD computers, partly because the problems an MISD computer can calculate are uncommon and specialized.
Single Instruction, Multiple Data (SIMD) computers have several processors that follow the same set of instructions, but each processor inputs different data into those instructions. SIMD computers run different data through the same algorithm. This can be useful for analyzing large chunks of data based on the same criteria. Many complex computational problems don't fit this model.
Multiple Instruction, Multiple Data (MIMD) computers have multiple processors, each capable of accepting its own instruction stream independently from the others. Each processor also pulls data from a separate data stream. An MIMD computer can execute several different processes at once. MIMD computers are more flexible than SIMD or MISD computers, but it's more difficult to create the complex algorithms that make these computers work. Single Program, Multiple Data (SPMD) systems are a subset of MIMDs. An SPMD computer is structured like an MIMD, but it runs the same set of instructions across all processors.
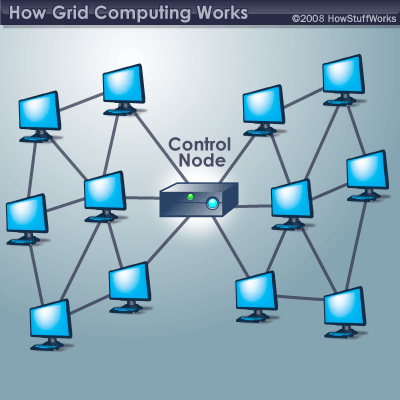
Out of these four, SIMD and MIMD computers are the most common models in parallel processing systems. While SISD computers aren't able to perform parallel processing on their own, it's possible to network several of them together into a cluster. Each computer's CPU can act as a processor in a larger parallel system. Together, the computers act like a single supercomputer. This technique has its own name: grid computing. Like MIMD computers, a grid computing system can be very flexible with the right software.