A scientist studying proteins logs into a computer and uses an entire network of computers to analyze data. A businessman accesses his company's network through a PDA in order to forecast the future of a particular stock. An Army official accesses and coordinates computer resources on three different military networks to formulate a battle strategy. All of these scenarios have one thing in common: They rely on a concept called grid computing.
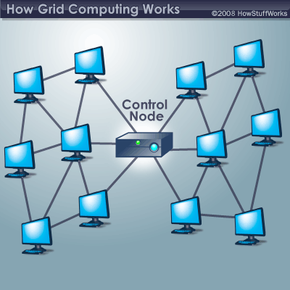
At its most basic level, grid computing is a computer network in which each computer's resources are shared with every other computer in the system. Processing power, memory and data storage are all community resources that authorized users can tap into and leverage for specific tasks. A grid computing system can be as simple as a collection of similar computers running on the same operating system or as complex as inter-networked systems comprised of every computer platform you can think of.
Advertisement
The grid computing concept isn't a new one. It's a special kind of distributed computing. In distributed computing, different computers within the same network share one or more resources. In the ideal grid computing system, every resource is shared, turning a computer network into a powerful supercomputer. With the right user interface, accessing a grid computing system would look no different than accessing a local machine's resources. Every authorized computer would have access to enormous processing power and storage capacity.
Though the concept isn't new, it's also not yet perfected. Computer scientists, programmers and engineers are still working on creating, establishing and implementing standards and protocols. Right now, many existing grid computer systems rely on proprietary software and tools. Once people agree upon a reliable set of standards and protocols, it will be easier and more efficient for organizations to adopt the grid computing model.
So what exactly is a grid computing system? Keep reading to find out.
Advertisement