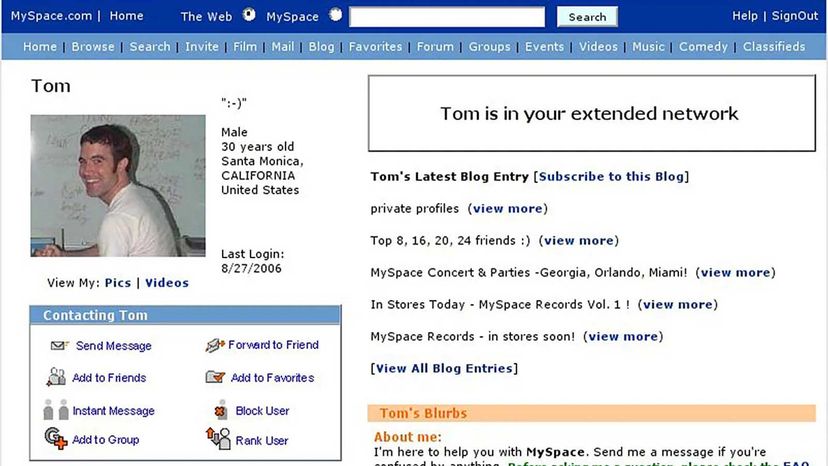
The internet plays a central role in our lives. I — and many others my age — grew up alongside the development of social media and content platforms.
My peers and I built personal websites on GeoCities, blogged on LiveJournal, made friends on Myspace and hung out on Nexopia. Many of these earlier platforms and social spaces occupy large parts of youth memories. For that reason, the web has become a complex entanglement of attachment and connection.
Advertisement
My doctoral research looks at how we have become "databound" — attached to the data we have produced throughout our lives in ways we both can and cannot control.
What happens to our data when we abandon a platform? What should become of it? Would you want a say?
Advertisement