On the Web as it is normally implemented, there are Web servers that hold information and process requests for that information (see How Web Servers Work for details). Web browsers allow individual users to connect to the servers and view the information. Big sites with lots of traffic may have to buy and support hundreds of machines to support all of the requests from users.
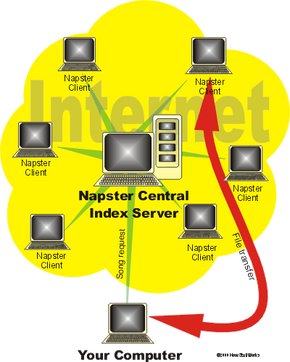
Napster pioneered the concept of peer-to-peer file sharing. With the old version of Napster (Napster relaunched itself in 2003 as a legal, pay-for-music site), individual people stored files that they wanted to share (typically MP3 music files) on their hard disks and shared them directly with other people. Users ran a piece of Napster software that made this sharing possible. Each user machine became a mini server.
If you logged into the old Napster to download a song, here's what happened:
- You started the Napster software on your machine. Your machine became a small server able to make files available to other Napster users.
- Your machine connected to Napster's central servers. It told the central servers which files were available on your machine. So the Napster central servers had a complete list of every shared song available on every hard disk connected to Napster at that time.
- You typed in a query for a song. Let's say you were looking for the song "Roxanne" by The Police. Napster's central servers listed all of the machines storing that song.
- You picked a version of the song from the list.
- Your machine connected to the user's machine that had that song, and downloaded the song directly from that machine.
The creator of Napster had a couple of reasons for this approach:
- Napster eventually grew to have billions of songs available. There is no way a central server could have had enough disk space to hold all the songs, or enough bandwidth to handle all the requests.
- Napster was trying to take advantage of a loophole in copyright law that allows friends to share music with friends. The legal concept behind Napster was, "All of these people are sharing the songs on their hard disks with their friends." The courts did not agree with that logic, but it gave Napster enough time to prove the concept and grow to massive size.
This approach worked great and made fantastic use of the Internet's architecture. By spreading the load for file downloading across millions of machines, Napster accomplished what would have been impossible any other way.
The central database for song titles was Napster's Achilles' heel. When the court ordered Napster to stop the music, the absence of a central database killed the entire original Napster network.
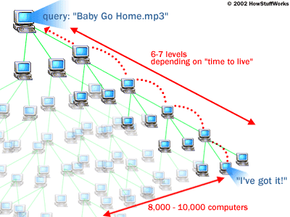
With the original Napster gone, what you had at that point was something like 100 million people around the world hungry to share more and more files. It was only a matter of time before another system came along to fill the gap.