The World Wide Web is an interesting paradox -- it's made with computers but for people. The sites you visit every day use natural language, images and page layout to present information in a way that's easy for you to understand. Even though they are central to creating and maintaining the Web, the computers themselves really can't make sense of all this information. They can't read, see relationships or make decisions like you can.
The Semantic Web proposes to help computers "read" and use the Web. The big idea is pretty simple -- metadata added to Web pages can make the existing World Wide Web machine readable. This won't bestow artificial intelligence or make computers self-aware, but it will give machines tools to find, exchange and, to a limited extent, interpret information. It's an extension of, not a replacement for, the World Wide Web.
Advertisement
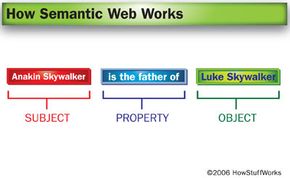
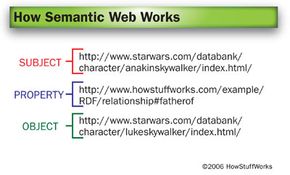
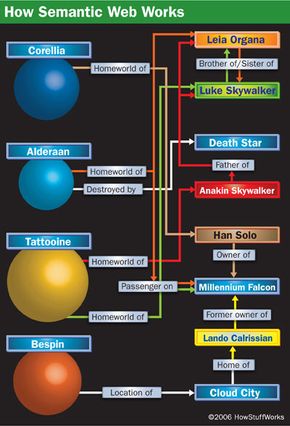
That probably sounds a little abstract, and it is. While some sites are already using Semantic Web concepts, a lot of the necessary tools are still in development. In this article, we'll bring the concepts and tools behind the Semantic Web down to earth by applying them to a galaxy far, far away.